采用目前世界最新3D角色软件创建逼真的人物,结合引擎动画驱动,连接AI大模型训练系统,进行高精智能体角色开发。
高精建模角色 形象逼真自然 动作栩栩如生
我们采用一个完整的角色创建解决方案,设计师创建风格化或逼真的角色资产,可用于 iClone、Maya、Blender、Unreal Engine、Unity 或任何其他 3D 工具。将业界领先的 3D 工具串联起来,完成 3D 角色生成、动画绑定、资产管理、高级视效渲染和交互式设计。
汇入任意角色

角色可扩展性
角色库,利用角色设计、类人形角色导入,或自动绑定静态网格物体等功能,提供角色设计师最大的可用性。 选择细分并导出角色以获得高精度的渲染,或精简角色规格以用于手机应用进程或群众模拟。
超擬真即時人物渲染。3D 人物角色具備甲尚科技的數位人皮膚、眼睛、牙齒與頭髮著色器,搭配 SSS (次表面散射) 與微觀法線技術。利用 CC 著色器製程以及指定專業貼圖來創建幾可亂真的數位人。享受為靜態藝術作品設計或 live 動畫表演而生的快速高品質即時渲染結果。

完整 3D 角色设计
多合一 3D 动画工具,用于设计逼真角色、轻松调整角色外型、定义皮肤外观、改变发型、测试着装、导入和绑定全新角色资产,甚至从照片创建角色。
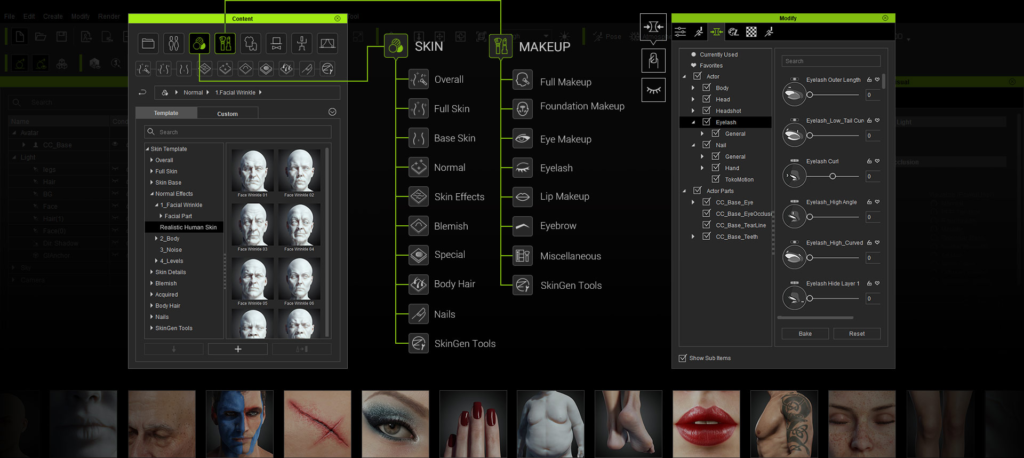
可扩展表情设置档
根据用户选择的项目类型提供两个等级的「表情设置档」。用于「标准级」的 60+ 变形兼容所有的脸部动捕,比如 ARKit,且对交互 XR 或游戏性能友善。用于「延伸级」的 140+ 变形则精准控制角色表情的细微差异,适用于拟真制作或 AI 驱动的数字人物。
表情范本
- 大量一键套用的表情数据库,依情绪状态分类为快乐、悲伤、生气、反感、恐惧及惊讶,并可再调整表情强度级数。
- 可组合来自不同面部区域的表情。
- 提供额外舌头姿态及 FACS。

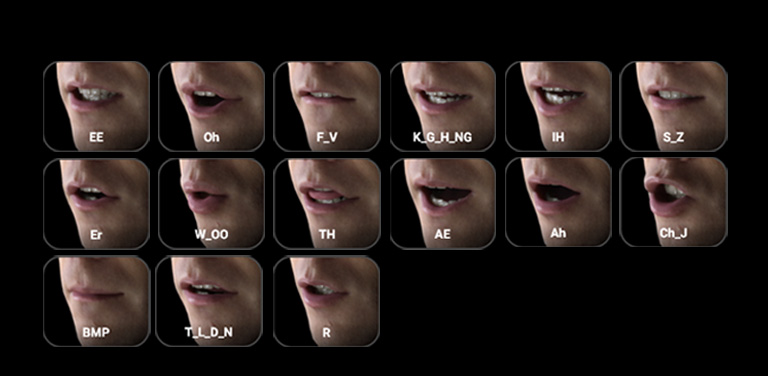
设置对嘴嘴型
嘴巴形状自订功能用于 CC 替身及人形角色。依设置,所有 CC 角色皆支持 8 唇形加 7 舌形的「音素配对」。想要带入自订扫描模型或风格化角色,则可利用更易对应的 1:1 嘴型(单音单形)。
直觉肌肉运动
- 拖曳鼠标以驱动沿着眼皮、眼球、眉毛、脸颊、嘴唇及鼻子部位对应的肌肉运动。
- 对称及连动「头部旋转」之选项。
- 可调式表情纳入细节用以极限操作。
- 除了支持具有 140+ 扩展面部轮廓的额外肌肉控制,亦支持更多用于嘴唇、眼睛、舌头的子菜单,以及用于睫毛、眼球(瞳孔)、颈部和耳朵的四个额外控制。
支持多种大屏
角色设计师和 IP 能够创建跨平台的 3D 角色资产,从超逼真的数字人到用于游戏和电影的风格化卡通人物,再到用于商业模拟的轻量 3D 人物。

AIEASE AIGC学院
文化与科技融合创新 共同探索人工智能应用价值场景
-AI主编: DigiKK