OpenAI GPT-4o mini,最具成本效益的小型模型。让智能变得更加实惠,显著扩大使用 AI 构建的应用程序范围。GPT-4o mini 在 MMLU 上的得分为 82%,GPT-4o mini 在 MMLU 上的得分为 82%,目前在 LMSYS 排行榜上的聊天偏好方面优于 GPT-4。它的定价为每百万输入代币 15 美分,每百万输出代币 60 美分,比之前的 Frontier 型号便宜一个数量级,比 GPT-3.5 Turbo 便宜 60% 以上。
GPT-4o mini 以其低成本和低延迟实现了广泛的任务,例如链接或并行化多个模型调用(例如,调用多个 API)、将大量上下文传递给模型(例如,完整的代码库或对话历史记录)的应用程序,或通过快速、实时的文本响应与客户互动(例如,客户支持聊天机器人)。
目前,GPT-4o mini 在 API 中支持文本和视觉,未来还将支持文本、图像、视频和音频的输入和输出。该模型具有 128K 个 token 的上下文窗口,每个请求最多支持 16K 个输出 token,并且拥有截至 2023 年 10 月的知识。得益于与 GPT-4o 共享的改进的 tokenizer,处理非英语文本现在更具成本效益。
具有卓越文本智能和多模态推理能力的小模型
GPT-4o mini 在文本智能和多模态推理方面的学术基准测试中超越了 GPT-3.5 Turbo 和其他小型模型,并且支持的语言范围与 GPT-4o 相同。它还在函数调用方面表现出色,这可以使开发人员构建获取数据或使用外部系统采取行动的应用程序,并且与 GPT-3.5 Turbo 相比,它的长上下文性能有所提高。
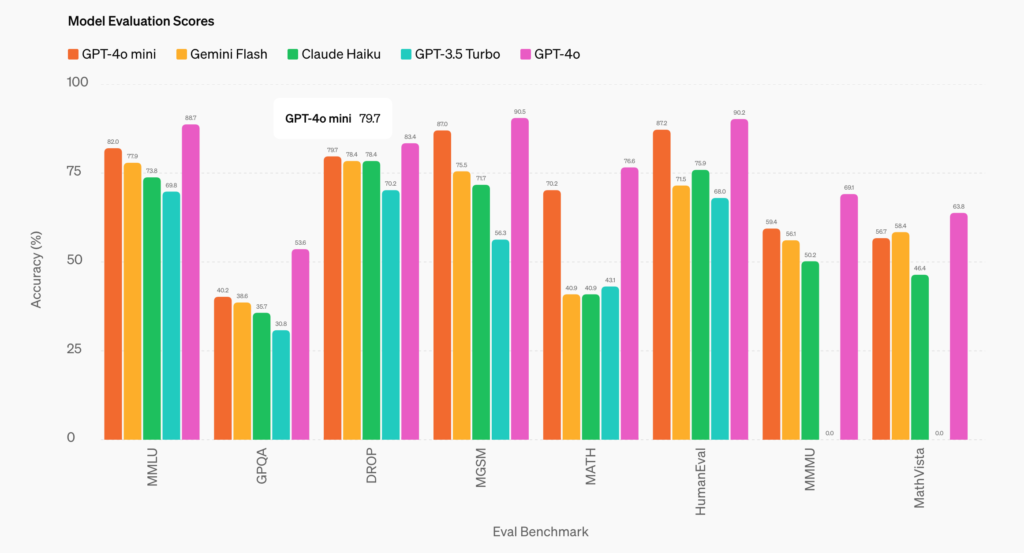
GPT-4o mini 已经在几个关键基准上进行了评估2。
推理任务: GPT-4o mini 在涉及文本和视觉的推理任务上优于其他小型模型,在文本智能和推理基准 MMLU 上的得分为 82.0%,而 Gemini Flash 为 77.9%,Claude Haiku 为 73.8%。
数学和编码能力: GPT-4o mini 在数学推理和编码任务中表现出色,优于市场上之前的小型模型。在测量数学推理的 MGSM 上,GPT-4o mini 得分为 87.0%,而 Gemini Flash 得分为 75.5%,Claude Haiku 得分为 71.7%。在测量编码性能的 HumanEval 上,GPT-4o mini 得分为 87.2%,而 Gemini Flash 得分为 71.5%,Claude Haiku 得分为 75.9%。
多模态推理: GPT-4o mini 在多模态推理评估 MMMU 上也表现出色,得分为 59.4%,而 Gemini Flash 为 56.1%,Claude Haiku 为 50.2%。